Everything You Ever Wanted to Know About Events and Logs on Ethereum


This article was originally published on Medium
Special thanks to Alchemy for reviewing the article, and to Richard Moore (Ricmoo) for reviewing some of the code. All images, including the cover image, were created and made ready for print by Linum Labs' own Michal Shachman.
Introduction
As part of a recent project, Linum Labs was contracted to build an API which could be used to scrape relevant data from a suite of deployed contracts. While scraping event data is a fairly routine operation in blockchain applications, we found a lack of practical guides or even detailed explanations for how to use existing tooling. Are you looking to scrape blockchain data, and can't figure out how to get the information you want from events? We hope this guide helps make your development process easier.
We'll start off with fairly obvious and high-level explanations that you can find in many places, and may very well know already. We'll gradually build up to what needs to happen in order to get the data from events fired on the blockchain, including code, eventually exploring the different tools available through the Ethers library. After that, we'll explore how to control how much data to get back.
If all you're looking for is functioning code, skip down to the "Finally! How to Decode Events From Logs" section for tools dealing with getting event data. We'll review any necessary information there. We'll also talk about a pretty clunky, somewhat functional, way to limit how much data you get back when querying the blockchain, along with a code implementation.
Events 101
Events are common in Ethereum smart contracts. Here's where Open Zeppelin declares some in their ERC20 Interface:
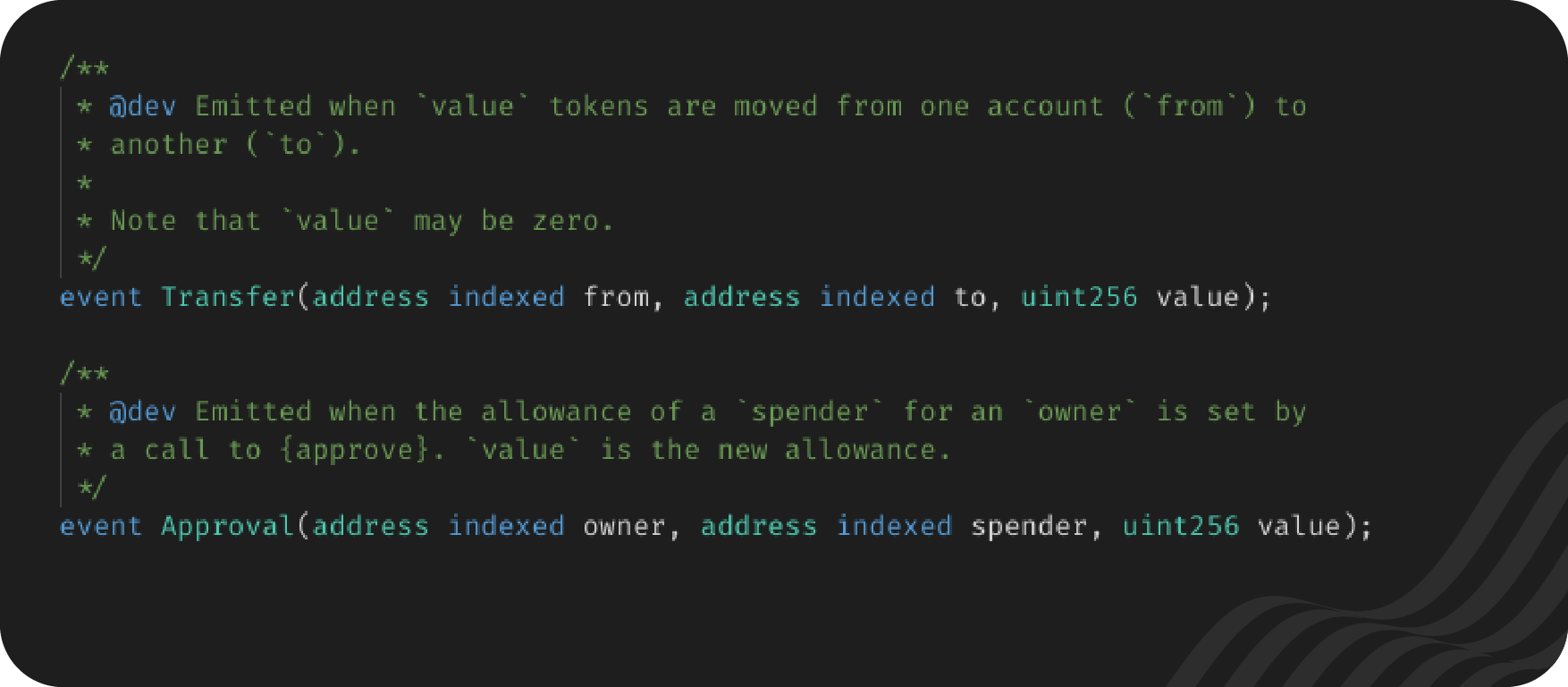
They are then called using the emit keyword. From Open Zeppelin's ERC20 contract:
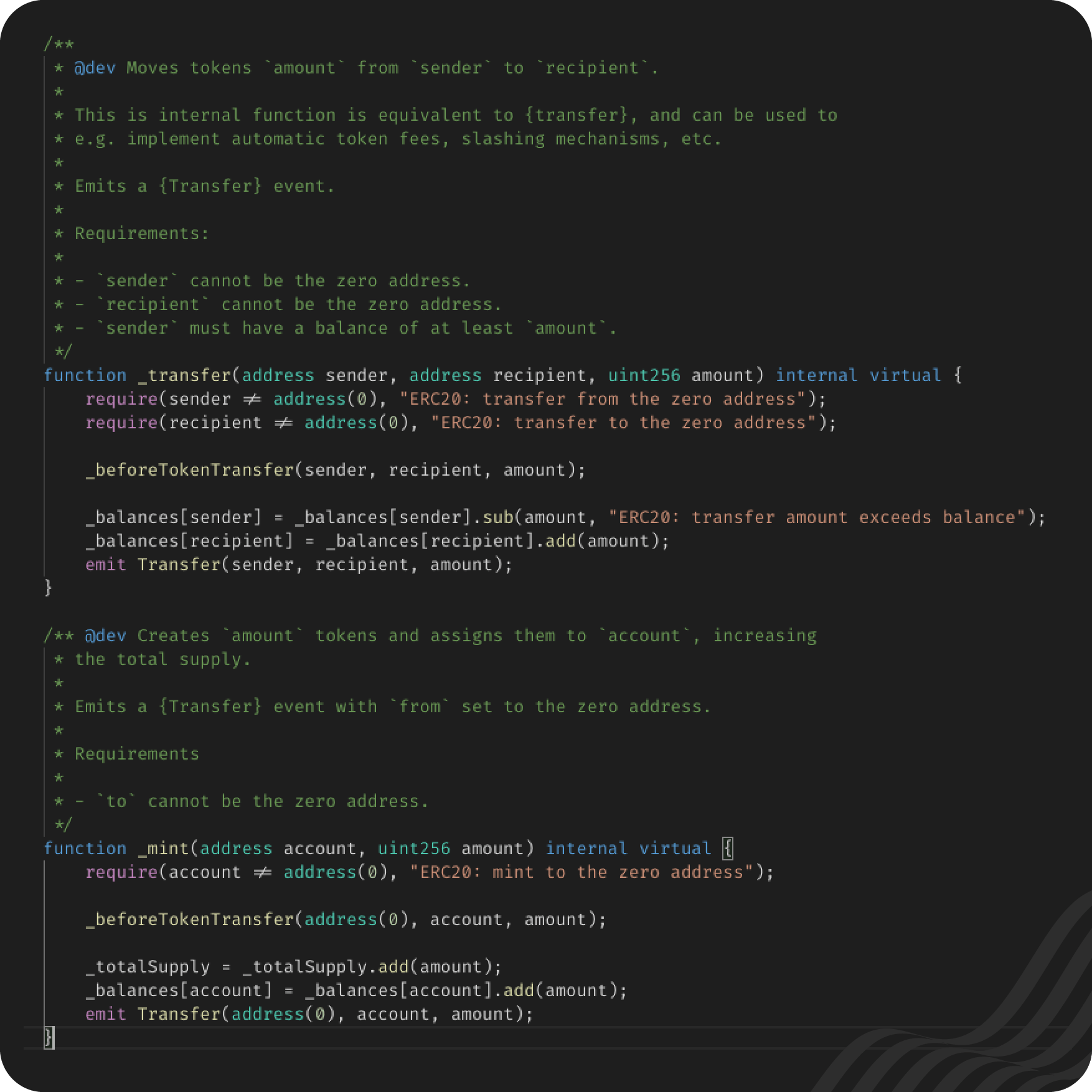
Do you notice the lines that start with emit at the end of the transfer and mint functions? They're making use of the Transfer event that is created in the screenshot above. Basically, the emit lines say that anytime these functions are called, they should create an Event following the format outlined above.
Events are called Events because they are very good at signalling that an event has taken place. In blockchain terms, they're cheap.
They're cheap to write in a contract in terms of deployment cost and gas cost when calling a function with an event, and they're free to read. In short, they're a very good way of broadcasting relevant information.
Then again, Ethereum already has something like that, in the form of Logs. Let's dig into those a bit, and then come back and compare Logs and Events.
Logs 101
Every block has a log, accessible via whichever tools you use to interact with the blockchain. Each block generates a log that has the following information:

Example is taken from https://codeburst.io/deep-dive-into-ethereum-logs-a8d2047c7371 , and appears with the permission of the author (Banteg)
You can ignore the fact that address, data, and topic are highlighted, though we'll be getting back to that in a minute.
Getting a bit meta, you'll see that there's a field called "logs" in the log. This contains a log object for every transaction in the block. We'll differentiate between the two by referring to the block log and log objects, the latter being the object in the array "logs" above.
If we already have logs built-in, what's the need for Events? There's a couple of ways we're going to answer that. You probably suspect that Events and Logs aren't entirely separate concepts, and you're right. They are interconnected. Remember how the address, data, and topic fields are all highlighted in the picture above? It turns out that these three are all related to events. I'm not going to explain this quite yet, though. First I'd like to develop the differences between logs and events a bit more.
Take a good look at the log above. It's got very general information in it. Useful, but limited. Even inside the log object all you find out is the address of the contract that fired a state-changing function, the block it did it in, and the transaction hash. Data is the data being sent/changed by the contract, so that too. What if I want to know who triggered the function in the contract? What if I want to know which other addresses may have had a state change (for example, receiving ERC20 tokens) as a result? The pure log alone won't be able to help with that. Here's the big reveal:
Events give you a way to add relevant logging data to the logs of a block.
That needs an explanation, though. What if I would tell you that the log in the image above has an ERC20 Transfer event in it? You certainly can't see anything like it there, can you? Well, as it happens, there is, and we're going to explain how to see that. I'd like to build this from the ground up, so if you're just looking for a code implementation, skip to the bottom. The tl;dr is that you can search for data from events with a couple of functions built into Ethers.js. (We have two implementations below, one for Ethers v5, and another for v4.)
How Logs Store Events
It may be useful to make a little tangent here about ABIs. Anyone who's dealt with implementing tools which interact with contracts has likely heard of them, but talking about them a little bit here should make explaining the next part just a little bit easier.
A contract's ABI is a lower-level representation of that contract. It contains all of the information that the contract has, but breaks it down into a JSON, detail by detail. If you use Truffle, Buidler, or any similar framework, part of your deployment process includes automatically generating contract ABIs as part of the process. You can search for them in a code editor and look at them there. (I don't know exactly where they'll be. If your contract is called erc20.sol, search for erc20.json in your project.) We're also going to go through an example here. Keeping up with the Transfer event from the ERC20 standard, the event looks like this in the ABI:
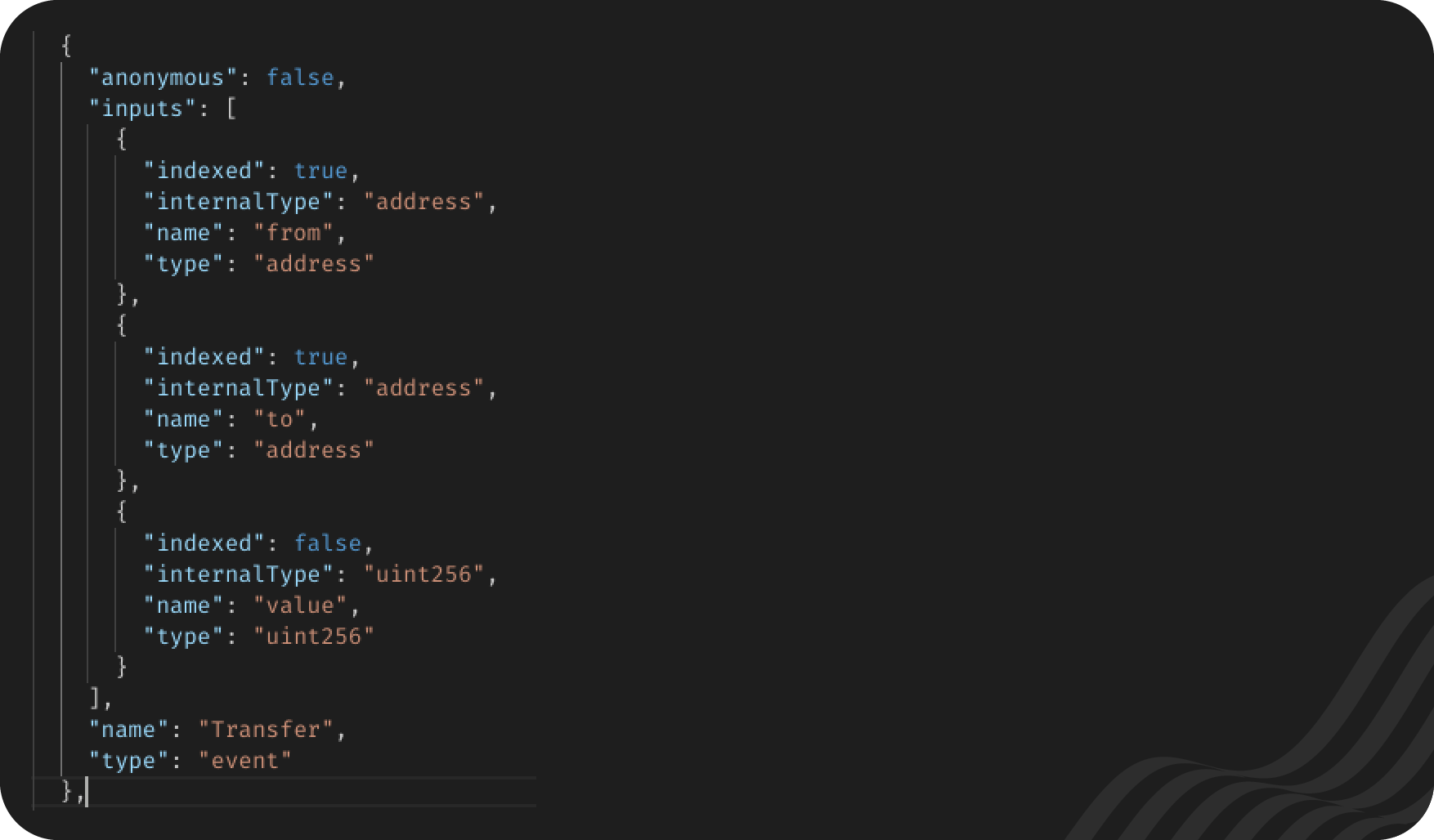
Due to the weird way that computers work as compared with human perception, start at the bottom. There the type field says that this object represents an event and that its name is Transfer. Up from there is an array of objects called inputs. Each object, when you look at it, represents one of the arguments of the Transfer object. Each object, or argument, has four fields. Again, let's go from the bottom up:
- type tells us what the data type is. Here to and from are addresses, and value is a uint256.
- name is the name of the argument. Transfer's arguments are from, to, and value.
- I'm actually not sure what internalType does. Please enlighten me in the comments.
- indexed is important, but we're going to take a raincheck on explaining it.
There's a concept that may seem a bit abstract now, but will be useful in a minute. One way we could represent some of the information above would be to take the name of the event, and then pair it with the types of inputs. In the case of Transfer, it would look like this:
This is called an event signature, sort of a compact way of referencing an event. They're going to come back up soon.
Before moving on, let's take another look at the log screenshot from before:
We pointed out before that the address, data, and topics fields were highlighted. This is because they are our key to deciphering events from logs. Remember how we defined event signatures above? Humor me for a minute. What do you think the result of hashing Transfer(address,address,uint256) is (no spaces in the parentheses, using keccak256) ?
You can try this yourself here: https://emn178.github.io/online-tools/keccak_256.html
If you take a look at the log above, you'll notice that this same hash appears in topics. Now you can start to see that topics is trying to tell us that there was a Transfer event triggered in this block.
What about the actual data in the event, though, like the actual values of from, to, and value in this transfer? That's where the data field comes in. The data for this event (in this case, see below) is stored here.
This is where the indexed field in inputs (in the ABI object we discussed above representing the event) comes into play. You'll notice in the screenshot of the ABI above that all three are set to false. If indexed would be set to true on any of them, that input would be stored as a separate topic, instead of being stored all together in data. There can be up to four topics in a log object, so technically all three could be set to true, at least as far as I know. I actually modified the ABI I used for a screenshot above to reflect the log object in the screenshot. Both addresses (from and to) had been generated as "indexed": true in the original, which means in the events fired from that, the addresses would appear in topics instead of data.
Before we really start pulling it apart, here's the data field all by itself:
I'm going to need to admit the boundaries of my own knowledge here. In this particular case where the arguments are addresses and a uint256, tricking them out of the data is sort of easy. The from address is the first series of numbers that aren't zeroes (well, sort of, it actually turns out the address is 0x0035fc5208ef989c28d47e552e92b0c507d2b318), the to address is the next one, and the value is the numbers at the end. Obviously, we'd prefer the amount in our normal 10-numeral system, and it's represented here in hexadecimal, but that's easy enough to convert. (It's 107696, for the record.) I don't really know how strings and other non-number data structures would be encoded, nor am I even sure about other uint data structures. I'd assume bools are 1 for true and 0 for false but don't know that for a fact, either. I also don't know how the amount of zeroes used for padding is determined. If you're very determined to dig deeper in this, you are essentially trying to build an ABI coder and can try to parse (haha hilarious pun) the ABI specification in the Solidity docs: https://solidity.readthedocs.io/en/v0.7.0/abi-spec.html
(Later note: with some help from Elan at Alchemy (thanks!), we were able to figure out a bit about the encoding format.
The data in the example is 192 bytes, which is a multiple of 64. You can check for yourself this Etherscan link to the transaction in the example. (Cryptokitties!) At the end of this section, the ABI spec says that encoding lengths need to be multiples of 32. My assumption would be that there is a set amount of bytes taken by each data type (like 256 bits for a uint256, then it's zero-padded to the left up to the next multiple of 32, but that's a guess.)
On the bright side, I can tell you that you don't actually need to know all that to decode the topics and data. Whatever language you're using to interact with the blockchain, there should be some library in it that decodes ABIs, likely there's even some functionality in whichever library you're using, and that's what you need here. I'll be using Ethers.js code in the example here.
Note: I haven't actually tested this, and anyway please don't use this for anything important when you have actual helper functions that will do the job better.
First, we'll need to grab the logs we want to pull the events out of. I'll assume you already have a provider called provider. If you don't, look up how to do this in the docs of whichever library you're using to connect to the blockchain. We'll use the example above for address and topic.
(As usual, there's some trouble getting this to format normally on Medium.)
Now let's take those logs and get the unindexed events out of the data. I'll assume you've gotten the events out of the ABI. There's an example of how to do that down below (in the section with some full code examples), if you'd like to know how to do it:
This would work a little bit differently with indexed inputs. You'd call decode on each topic which is an argument value (not the first topic, that one is the event signature), and only pass in the type for that topic. Let's say from and to are indexed as the second and third topic (since the first is always the event signature), you'd call:
You may have to work a bit with whatever is returned to get the data you need. A more detailed implementation is outlined in the code examples section below.
So now you'll be able to decode the data and topics of an event that you're looking for, assuming you know the name of the event, and the data types of the arguments it takes. We'll be taking a similar path to do this in a minute, where we'll create an Interface out of the whole ABI, but this is the low-level way to decode event data, and I hope it gives you a better idea of what's going on.
Getting the Logs You Need
We now have the ability to hash an event signature and see if it's in the topics and can decode the topics and data. But how are you supposed to get the log objects? The more important question, you'll discover, is how do you get the log objects that you need? Blockchains are large. Ethereum's mainnet is over 10 million blocks. You don't want to accidentally make some call which tries pulling the entire chain's logs.
I'll be using Ethers as an example again. In Ethers you'll be using the getLogs function. Just calling getLogs would return logs from the entire chain, but there are also filters that can be passed in as arguments.
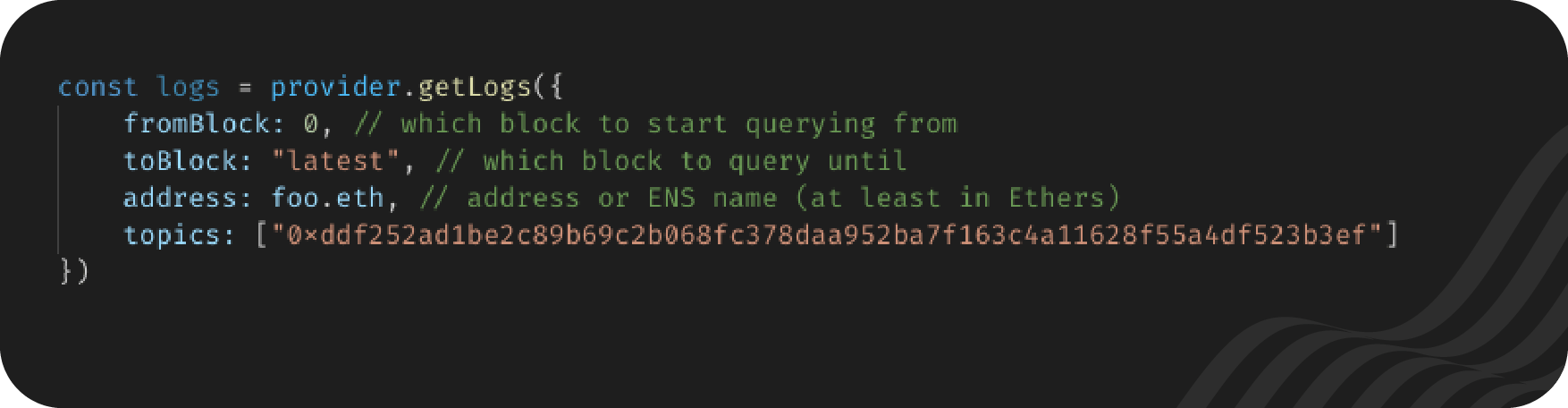
I figure that with everything above, the topics entry is self-explanatory. (It's the hash of the event signature, and we discussed above what that means.) You might notice that the topic above is the event signature for the ERC20 Transfer event.
A quote from the old Ethers docs might be useful here:
For the vast majority of filters, a single topic is usually sufficient
All of these filters are optional, but you'll likely throw an error if you don't use any, which may even be better than the alternative, which would be asking for every single log object in the history of the blockchain. If you're looking for logs from a specific contract, try to find what address it was deployed to, and use the address as the filter. If you only know around when it was deployed, find what block you can start from. If you don't need to check until the present day, put an upper bound using toBlock.
This will return an array of log objects like the one used in the screenshots above. We're now ready to get to work decoding some events!
Finally! How to Decode Events From Logs
All examples assume an address to an ERC20 contract passed in as a string and look for the Transfer event. You'll need the ABI of the contract, too. You'll also need a provider, which is the general web3 term for the object you connect to the blockchain through. If you don't know what that is, I honestly admire your determination for making it this far, and you should be able to find out how to instantiate one in the documentation to whichever framework you might be using. They're pretty much the backbone of any web3 scripts, so make sure you figure them out. That being said, here's a few words on the subject: If you want to be able to interact with the blockchain, or even just read from it, you need some kind of connection to the blockchain.
You might be running a node locally (or even remotely). If so, the provider will connect to the blockchain through your node. You might not be running your own node, though, in which case the easiest solution is using a Node-As-A-Service provider. Alchemy is a service that recently came out of stealth that offers a range of blockchain data management services, including exposing a provider. Infura, a ConsenSys spoke, is probably the most famous name in the space.
After a conversation with Richard Moore, the author of the Ethers library, there's something I'd like to expand on a bit more. Something we'll dive into later is that traditional APIs will pretty much always have a built-in option to only get and send a certain amount of results. The blockchain does not. The solutions we give here do not work at scale. This is one reason why the focus is on getting a specific event from a specific contract. I also think this is one of the most useful applications of event scraping. If you have contracts you're deploying and playing around with, events are, at the end of the day, the best real-time indicators of what's happened with them. If you are in need of scaling options, finding solutions like Alchemy or looking into an implementation of The Graph are probably your best bets.
The only version of the scripts below that I have tested is the Ethers v4 script. I'm pretty confident in the Ethers v5 script too, and significantly less sure of the first script below, which is meant to be more illustrative than practical. Richard Moore confirmed that it should basically do what it's intended to do. It still shouldn't actually be used in production. If you do find a bug or mistake in any of the code below, please let me know!
The Hard Way
There's a super simple way to do this using Ethers v5, and a fairly easy one using v4, but if we've made it this far, what's the fun in doing it the easy way? Also, dear reader, I don't know if you need this for a project that would be hard to update to v5, or if you're using a completely different framework that doesn't have built-ins like Ethers v5 (or v4) does. As such, first, we'll do it the hard way. It also serves an illustrative purpose, giving a code implementation to everything we've discussed above.
One caveat is that you'll need to know what tools are available in whichever language you use.
The code below is in JavaScript, which almost certainly has the most tools for interacting with the blockchain, though libraries exist in Python, Java, Haskell, and I'm sure even more. While the exact commands here will likely not work for you, I hope they can give you enough insight to be able to find them in your own framework. If all else fails, there's always bugging the author of your favourite framework on the internet.
To be honest, a quick scan of a few other web3 libraries for other languages seems to turn up useful event-scraping functions, so your first step really should be to try and find them. It's meant to be helpful in understanding what is going on when you're scraping an event far more than actually being intended to be implemented.
For this recipe, all you will need is the contract ABI, and the contract's address for the contract that holds the event that you're looking for. (Having the event signature (as explained above) wouldn't hurt, though the code shows how to derive it.) You will need access to an ABI encoder/decoder — I'd be out of my depth trying to provide that. I know Ethers provides access to this in their low-level API, but don't know the particulars for each framework.
Please forgive the line wraparounds — some things that are meant to be on one line wrap on to the next. There's a link to a more generalized version of this function in a gist on GitHub in the discussion right after this, it might be more convenient for you.
It's worth pointing out that you can tell from where we pull out the from and to addresses and amounts that even once the events are decoded, the actual data is stored inside "values" in the event object, not at the top level.
Also, this implementation assumes that you're looking for a Transfer event with from, to, and value values (as in the ERC20 standard). I've made a gist with a more generalized function in case you want to play around with this a bit more here: https://gist.github.com/wschwab/528153cb6f2ea17ef9eee0c180425961
It takes in four arguments: the address of the contract on-chain, the ABI of the contract, a string with the name of the event you're looking for (like "Transfer", with the quotation marks), and the Ethers provider. (It assumes you're using Ethers, as does the script above, in order to use the keccak hashing function, and for the ABI decoder. Theoretically, at least, the provider probably could come from a different library, though if you're already using Ethers for those, I know of no reason not to use it for the provider too.)
You could most likely generalize the function more in order to not only filter one event on one contract. Be careful of making requests that bombard you with too many results.
Ethers v4
Here all you'll need is the contract address and ABI. A cool thing called an Interface will do all the rest for you.
The Interface that is created is a really cool helper. It derives the event signatures and topics, and then just parses the log looking for them.
As with the previous example, this script assumes that you're looking for a Transfer event with from, to, and value values, though it can be easily generalized to other events. If you're having trouble getting the data you want, you may want to try returning or console.logging the decodedEvents just to see what the objects being returned look like.
Ethers v5
Ethers v5 makes things easiest of all. You still need the ABI and the address, but after that it's all easy-shmeasy:
As with the previous examples, this script assumes that you're looking for a Transfer event with from, to, and value values, though it can be easily generalized to other events. If you're having trouble getting the data you want, you may want to try returning or console.logging the decodedEvents just to see what the objects being returned look like.
Pagination — Controlling the Blockchain Data Fire Hose
Originally I thought, yay! We did it! That's it, time to pack the bags and go home. We soon discovered another key difference between dealing with classic data and dealing with blockchain data. Most APIs have some sort of limiter built in so that you don't suddenly and surprisingly get hit with a massive amount of responses. Blockchain has no such measure in place. In my experience, my server would autofail any request that tried to pull more than 10K responses, I don't recall if that was built into Ethers, or a part of the underlying Node.js architecture (I suspect the latter), but this is hardly convenient if you're trying to build a dashboard that displays relevant data, and you're suddenly populating a table with hundreds of rows where you didn't expect it. It was pointed out to me that it's even worse if you start getting back so much data that your computer's I/O is overwhelmed. Wouldn't it be nice if there was some way of controlling how much data you got back from a request?
Again, SQL, noSQL, and even plain old APIs usually have something like this built-in; you don't usually need to build something like this in a server. I am assuming that this is why I couldn't find anything to help me do this, and in the end am looking to home-bake a solution.
(One solution you might see is a rate limiter. The rate limiters I've seen operate by allowing you to determine how long a request should run. While I didn't play around with this, my assumption would be that it wouldn't work very well. Not only are not all blocks created equal, some are far more full than others, the nature of the network itself should make for very inconsistent retrieval times. If I've made a mistake in my assumptions here, please set me straight.)
Let's review something before we discuss the methodology behind our implementation. When we were looking to scrape event data above, we didn't want to pull every log from the whole chain, only the ones from the contract we were interested in. That's why we filtered the getLogs request by address, putting in the address of our contract.
That's not the only parameter you can filter by, though. You can also choose what block the getLogs request should start from, and which block it should go until. We should be able to use a while loop to step block by block using those filters until we've gotten as many responses as we'd like. We'll see that this isn't a perfect solution, you can end up with more responses than you want, but it should be fairly close to accurate. It's terrifically slow, too.
Just to step through the process before the code: we'll need to initialize an empty array to hold our logs, and query the chain to see what the latest block number is. (This assumes that you want to step through from the most recent back, which I assume is the most likely scenario. It can be adapted to other needs easily, though.) We'll then set a while-loop to run while the length of the array hasn't hit our target number of responses. In the loop we'll request the logs for the most recent block, push them to the log array, and decrement the variable for which block we're checking. This should return the log objects block by block until the target number of responses is hit.
This means that we may end up with more responses than we asked for. If we want, say, 50 responses, and the array already has 49, then it will move back a block and start the loop again. If in the next (or previous, depending on your point of view) block there were two separate events, it will pull both, leaving you with 51 responses instead of 50. A quick perusal of events on DAI shows that DAI does indeed often generate multiple Transfer logs per block, I saw as high as 11 in one block. Then again, most things don't have DAI's traction. Also, check why you need a specific number — if it's for UX, it's unlikely that the UX will deteriorate much even if the last block is a monster with 15 events. This led me to believe that the overflow is inconsequential. If you really want to ensure precision, you can take a slice of the first 50 items in the array before returning it.
Let's take a look at some code! I'll be including the code from Ethers v5, though it could be easily adapted to v4. I'm just including it so there's a bit more context. There's a link to a gist afterwards, which may be easier than trying to read the code in Medium:
There's also a more general purpose gist version of this here: https://gist.github.com/wschwab/6e89eeb29a8e24203ee954c042e47a6f
You'll see that we've added an argument for how many responses the getLogs should retrieve, and then wrapped the getLogs in a while-loop like we discussed above. If you'd like to test this out, I tested this by pointing it at the DAI contract on mainnet, though bear in mind that you should use DAI's ABI for this, at least as far as I can tell. You can find both the contract address and the ABI here on Etherscan. (The ABI can be found by accessing the 'Contract' from the bar of options that defaults to showing the transactions about halfway down the screen. Once you've selected 'Contract', scroll down. There's an ABI section which even has a tool for copying the ABI to your clipboard.)
You might notice that this function only returns logs, but you could easily extend it to extract events from the logs, or even run the loop until a certain number of a certain kind of event have been found, and even build out the function by having it take an event name as an argument.
The next steps in making this concept a bit more useful would probably be optimizing how many blocks to load in each loop and parallelization. Right now the while loop goes block by block. It will depend on your use case and your margin of error, but taking more blocks on each iteration of the loop would speed things up significantly. Running in parallel (parallelization) would be the next obvious speed up.
One more addition to this topic: I'm sure you're familiar with sites that load some items, but then as you scroll down, load more. What if you want to do that with your blockchain query? You want to have a table of DAI transactions, but don't want to load them all at once, but rather 50 at a time as the user scrolls down. What now?
I'm not going to give code implementation for this, since it really needs to be split across a few different files, and I feel like it would end up being more confusing. There's also more than one way to do this. We'll still give you an outline. Here's the basic rundown: On the frontend of the page or app, there should be a variable for the block the logs should be pulled from (let's call it startBlock). This should be passed in with the request, and should initially be set to the most recent block.
On the backend, the function above needs to be modified to take another argument — startBlock. blockNumberIndex will be set to the value of startBlock (taking out the query for the latest block), and then blockNumberIndex should be returned from the function with the event data. The API should return not only the event data, but also the last state of blockNumberIndex -1, which should be one less than the last block scraped for data.
Coming full loop, on the frontend, startBlock should be updated to the value of blockNumberIndex (which is being sent over by the API, like we just said), and triggered if the user scrolls to the current bottom of the table.
Conclusion
That was quite a bit! We've travelled through logs and events, understanding how the logs store events and even ended up with three different code implementations of how to get the events out of the logs, along with how to filter how many responses you get.
As Ethers shows, scraping events is getting easy enough to not need to understand everything that is going on under the hood, but it's always good to understand things deeper. You never know when it will come in handy.
If you find any bugs in the code, mistakes in the explanations, or generally have an idea of how we could improve this article, then please reach out in the comments. We'd like to make this article the best it could possibly be. We also accept compliments.
.jpg)


